
Zde najdete řešení příkladů ze cvik PS1. Řešení jsou má, tudíž nemusí být nejlepší, nejpřehlednější, nejefektivnější či vůbec správná. Ne vždy se vše dá stihnout na cviku nebo jsme na hodině problém vyřešili jinak než jsem ho řešil sám. Stránká má sloužit jako další zdroj informací, příkladů a ukázek k zamyšlení. Pokud něčemu nerozumíte, zeptejte se. Pokud vidíte chybu, nebojte se mi napsat např. na fb, mail bartimar at fit.cvut.cz nebo se zeptejte na askfit.cz. Za nápady a připomínky budu rád :)
SPOILER ALERT! Doporučuji si vyřešit příklady sám, když budete mít problémy nebo vám to bude dlouho trvat, hledejte tady.
echo $PAGER
PAGER='echo haha' man man
echo $PAGERPAGER='r\m -rf /' # Pouze na vlastni nebezpeci
alias ll='ls -l'
type ll
which ll
hash
PS1=\'\`date\ +'%T'\`\:\"\'\$PWD\"\>\
. .bashrc
print %q "$IFS"
set | grep IFS
ptree
echo $SHLVL
firefox vim-adventures.com &
vimtutor
chmod a-x pok
cd pok
for p in `date`; do echo $p; done
for p in "`date`"; do echo $p; done
for p in '`date`'; do echo $p; done
date
!!
!-2
!dat
history -h | tail -5 >date.sh
bartimar@fray1:~$ ls -l www_webdev
lrwxrwxrwx 1 root zam 25 Oct 7 09:01 www_webdev -> /home/www/webdev/bartimar
[ -L www_webdev ] && echo ok
[ -L www_webdev/ ] && echo ok
cut -d: -f6 <<<"$PATH"
touch {1..5}.{sh,py,c}
tar cf archiv.tar *.{sh,py,c}
less archiv.tar
paste -d:,\n -s file*
printf "%$(wc -L <$file)s\n" $(<$file)
cat /home/courses/BIPS1/public/schedule/304.html | sed 's/<a href="[^>]*">/|&|/g' | tr '|' '\n' | grep 'a href="[^m].*html">$' | sed -e 's/^<a href="//' -e 's/">$//' | sort -u # Buh prave zabil jednu kocicku. Google 'UUOC'Jak vyberete ze souboru “$DIR“/schedule/<číslo_cvičení>.html odkazy na další soubory?
cat /home/courses/BIPS1/public/schedule/304.html | sed 's/<a href="[^>]*">/|&|/g' | tr '|' '\n' | grep 'a href="[^m].*html">$' | sed -e 's/^<a href="//' -e 's/">$//' | sort -uJak odfiltrujete z logu “$DIR“/07/apache.log chyby ( [error] ) ?
cat /home/courses/BIPS1/public/07/apache.log | grep -v '\[error\]'Jak zjistíte počet požadavků GET, POST a HEAD?
cat /home/courses/BIPS1/public/07/apache.log | grep -c 'GET'Kdo poslal nejvíce požadavků, jaký byl nejčastější “error code“ (předposlední položka)?
cat /home/courses/BIPS1/public/07/apache.log | grep -v '\[error\]' | sed 's/.*HTTP\/.*" //' | cut -d\ -f1 | sort -n | uniq | grep -v '200'O jaký soubor se nejčastěji žádalo (zkuste vyfiltrovat multimediální soubory)?
cat /home/courses/BIPS1/public/07/apache.log | grep -v '\[error\]' | grep '"GET' | sed 's/.*"GET \([^ ]*\).*/\1/' | egrep '(.jpg|.gif|.png)$' | sort | uniq -c | sort -r | head -1
tr -s ' ' <apache.log | grep -v '\[error\]' | cut -d\ -f6 | sort | uniq -c | sort -nr | head -1 | grep -o '[0-9]*' | head -1awk '!/\[error\]/{a[$6]++}END{max=0;for(i in a){if(a[i]>max)max=a[i]} print max}' apache.logIFS=$'\n'
for i in `ls video/`; do mkdir -p video-"${i##*.}"; mv video/"$i" video-"${i##*.}"; doneTakže snadněji a lépe
for i in video/*; do mkdir -p video-"${i##*.}"; mv "$i" video-"${i##*.}"; doneypcat passwd?ypcat passwd | gawk 'BEGIN{FS=":| "; OFS=" "} $6 ~ /ova$/ || ( $5 ~ /[aei]$/ && $6 ~ /a$/ ){ print $5,$6}' | egrep -v '^(Jiri|Jose|Filipe|Lukas) 'Jak zjistíte četnost křestních jmen?
ypcat passwd | gawk 'BEGIN{FS=":| "; OFS=" "} $6 ~ /ova$/ || ( $5 ~ /[aei]$/ && $6 ~ /a$/ ){ print $5}' | egrep -v '^(Jiri|Jose|Filipe|Lukas)' | sort | uniq -c | sort -rKteré křestní jméno je nejčetnější? Oh come on.
/home/courses/BIPS1/public/08/names soubor/home/courses/BIPS1/public/08/names.awk ?cat /home/courses/BIPS1/public/08/names | gawk 'BEGIN{ print "#!/usr/bin/awk -f\nBEGIN { FS=\":/\" }" }{print "$5 ~ /^"$0" /"}'Grep nepodporuje \t jako tabulátor, což je vidět na obrázku. Buď můžete použít přepínač -P (perl), naučit se psát tabulátor (ctrl+v a zmáčknout TAB) nebo třeba ANSI quoting ($'\t') a další. Jo a bacha na vykopírovávání tabulátoru, taky vizte obrázek.
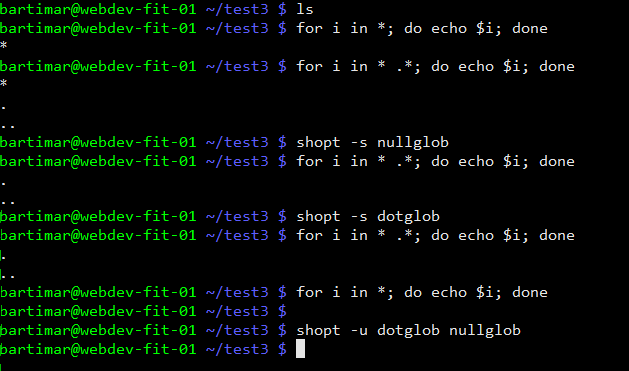
ls * vám v prázdném adresáři dopadne špatně se zapnutým nullglob (defaultně), hvězdička se nemá nač expandovat, tak se bere jako obyčejná hvězdička (neboli bash ji nechá a programu ls přijde jako argument, ten ale neví co s ní, snaží se pouze najít soubory s názvem hvězdička). Když tedy například přes for cyklus počítate počet souborů, zamyslete se, jestli vám fungují pro prázdný adresář. Nejspíš se vám občas bude i hodit nalézt skryté soubory, k tomu se vám může hodit dotglob.
Občas si lidi pletou kdy kde co má speciální význam. S regulárními výrazy se vše rázem zkomplikovalo. Pokud to nevím, tak si to jednoduše vyzkouším. Na obrázku je regex na match IP adresy (jednoduchý, ale ve většině případů bude stačit), pokud si ho vyzkoušíme jen jestli nám matchne nějakou random IP adresu, tak nemůžu říct ok a jít od toho. Bacha co všechno může tím matchem projít.

Nagenerujeme si nějaké IP adresy, ať si můžeme vyzkoušet tu naší sort hrůzu
echo {0..255}.37.{0..255}.214 | sed 's/ /\n/g' >someips
Kdo by chtěl více IP adres
echo {0..255}.{0..255}.{0..255}.214 >moreips &
Kdo si chce uvařit stroj
nohup echo {0..255}.{0..255}.{0..255}.{0..255} >allips &
Pokud to stihnete
pkill -p nohup
Jak se hezky sortí
shuf moreips | head -500 | sort -V
echo {a..Z} #ASCII tabulka
echo {{A..Z},{a..z}}
echo {{a..z},{A..Z}}{{a..z},{A..Z}}
sed 's#http://example.org/res/#zdroj: #'
./skript.sh r - x r w - - w - ./skript.sh 755
./skript.sh f r - x r w - - w - ./skript.sh f 555 ./skript.sh d r - x r - - - w - ./skript.sh d 645
3. Najděte všechny soubory v aktuálním adresáři s příponou .sh s právem spuštění pro kohokoliv a zároveň soubory s příponou .c a .h, ke kterým někdo přistoupil v poslední hodině nebo je jejich velikost větší než 1M a jejich název nezačíná řetězcem "common". Všechno nalezené zabalte do archivu s názvem archive.tar.
4. V Aktuálním adresáři zabalte všechny složky, každý zvlášť do archivu. Pokud je v aktuálním adresáři 20 složekm výsledkem je 20 archivů. Původní adresáře smažte.
Mohlo by se hodit:
Sociální sítě
Mám sociální síť, kde chci nahnat trochu followerů. Pomocí jednoduchého skriptu prošmejdím web a najdu spoustu uživatelů, ty dám follow a určitá část z nich mi dá follow back. Daná sociální síť má ale limit na počet sledovaných lidí, nedovolí mi tedy sledovat více jak 100 000 lidí. Z nich mi ale jen 10 % dalo follow back. Chci tedy vyhodit ty, jenž mě nesledují, ale já je ano. Sociální síť bohužel žádný takový seznam lidí neposkytuje. Jak si ho udělám sám? Mám k dispozici seznam lidí, co mě sledují a seznam lidí co sleduji já.
Formálnější popis problému: Ze souboru following.txt odstraňte všechny řádky souboru followers.txt
grep -v -f followers.txt following.txt > final Proč je to šíleně pomalé? Jak to udělat lépe?
First!
Pravidelně kontrolujte váš oblíbený kanál a při zveřejnění nového postu pošlete komentář "First!", ideálně i doplněn o nějaký random joke. Např. Cyanide & Happiness na facebooku.